
Unfolding the AI Narrative - Part 2
Local Maxima & The Frame Problem

Welcome to the Tales of a Cyberscout, where we explore topics ranging from active cyber defence to technology and society, all of it with a drizzle of zesty cynicism and philosophical gardening.
Recap: Intelligence Friction and Flow
Before we dig in, let's do a quick recap of my thoughts on intelligence, friction, and flow from Part 1 of the series.
In my view, intelligence isn't just about thinking. It's a fundamental force, a drive for agency within an environment, critically shaped by the need for self-preservation, i.e. having real "skin in the game". We defined intelligence as
a dispositional, emergent, and generative capacity for agency in an environment, underpinned by evolutionary pressures favoring self-preservation and adaptation.
This is where I see a key difference with what hype-sorcerers call AI: for me, it's a probability engine that lacks the inherent concern of finitude and risk.
In the organic world, self-preservation implicitly assumes you have an instinct that is tied to a body that defines that which should be preserved for your life to continue unfolding.
AI's attention mechanisms, driven by weights, cannot encode this factor because these probability engines don't know what part of their network they need to preserve to maintain a minimal functioning core.
While our human intelligence and AI are becoming increasingly co-dependent, AI's progress isn't seamless. In our last post, I posited we can understand its development much like electricity: facing resistance but driven by potential.
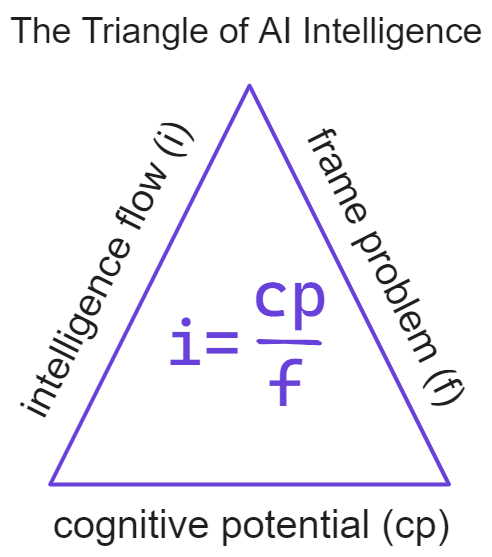
I identified two main frictions holding back AI: the "Frame Problem" which represents its struggle to interpret relevance in complex environments (f factor), and the "Cognitive Potential Problem", relating to its scalability and how deeply it's embedded in the world (cp factor).
So, when we ask "why not AGI yet?", I argue it's not just about insufficient computing power. It's because we haven't yet managed to sufficiently minimize this environmental resistance and maximize AI's cognitive potential through deep, distributed embedding into the everyday world, moving beyond a shallow AI to a truly integrated (deep) one.
Local Maxima
If you would have to come up with a different code solution every time you need to solve different instances of the same problem, then either it's not the same problem or you lack the capacity to solve concurrent instances of the same problem.
The first issue is a problem of pattern generalization, you are working with different instances of different problems and your computing network is not clever enough to realize that its dealing with different problems altogether, not just different instances of the same problem.
The second is a problem of scalability, you may be working with a high quantity of instances of the same problem, but your computing network cannot handle the extra workload without losing effectiveness (performance).
Both affect the efficiency in which AI can solve problems. The difference here matters though. Scalability is about handling more of the same, while generalization is about handling new.
A system that scales well might efficiently process millions of transactions, but that doesn't guarantee it can correctly interpret a slightly different input or pattern it hasn't encountered before (poor generalization). Conversely, a system with strong generalization capabilities can adapt to unfamiliar inputs, but might struggle to maintain that performance under a massive influx of data.
[[ slight digression: The underlying topic here is that of exploration / exploitation patterns (aka exploration / optimization) a fascinating topic I hope one day I can write a book about. ]]
We need to come up with a couple definitions now to continue our journey.
We shall call AI computing artefact to an automation system (a composition of hardware and software operating on computational principles) functionally defined by its achievement of a metastable balance between the capacity for broad generalization across diverse problem instances and the focused particularization required to effectively address specific characteristics of unique problems. Through this balance, it achieves both general consistency on known problem types and adaptive capability when facing novel situations.
We shall define the scalability problem as the engineering challenge in terms of resources and capability (technology and people) required to successfully develop, deploy, and sustain AI computing artefacts such that they achieve reliable, and efficient operation at scale.
The effectiveness of AI computing artefacts depends on their ability to both solve extremely granular and specific problems on the one hand, whilst capable of solving general problems on the other. On one end of the spectrum you would have unique problems that are not transposable at all, they are irreducible to a common denominator. On the other end you would have universal routines or algorithms that are used over and over to solve multiple instances of the same problem.
Non-AGI AI is locally generalizable but it's not universally generalizable, it cannot solve for most problems that deviate from what it was trained for.
In other words, current AIs lack adaptive generalization, they become local maxima in their domains of expertise and have to be semi-manually guided by humans to re-train in new specific domains.
In the context of AI, a local maximum refers to a state where a model performs optimally within a limited range of inputs or tasks, but its performance degrades significantly when faced with inputs or tasks outside that range.
The model has essentially become trapped in a sub-optimal solution space, unable to explore more generalizable solutions that would be effective across a wider variety of situations. This contrasts with a global maximum, which represents a solution that is optimal across all (most) possible inputs.
This issue of local maxima can be understood through the lens of the relationship between intelligence (i), cognitive potential (cp), and environmental friction (f). As established earlier:
i (intelligence) represents the capacity for agency, adaptation and complex behaviour.
cp (cognitive potential) represents the resources (computing power, scalability, embeddability) available to the AI.
f (environmental friction or the frame problem) represents the complexity and unpredictability of the environment.
The problem of local maxima arises from an imbalance between cp and f. It is a consequence of high f and limited cp.
Current AI models possess high cp and low f in their specialized domains. They often excel in specific domains because they are trained on narrowly defined datasets and optimized for particular tasks. This specialization can be seen as a way to manage the f factor (environmental resistance or the frame problem). By limiting the scope of the environment, the AI doesn't have to deal with the full complexity of the real world. However, this leads to a fragmented cp.
Each specialized AI model can be seen as residing in a "local maximum" of capability. It performs very well within its narrow domain, but it's unable to generalize or adapt to new, completely unseen contexts (i.e. a new, unexperienced f). This is because its cp is not structured to handle the broader range of possibilities. Embedding depth in our fully embodied world is shallow.
There is no equivalent to the emergent agency seen in natural intelligence, which can draw upon a wide range of specialized skills and knowledge to navigate complex situations.
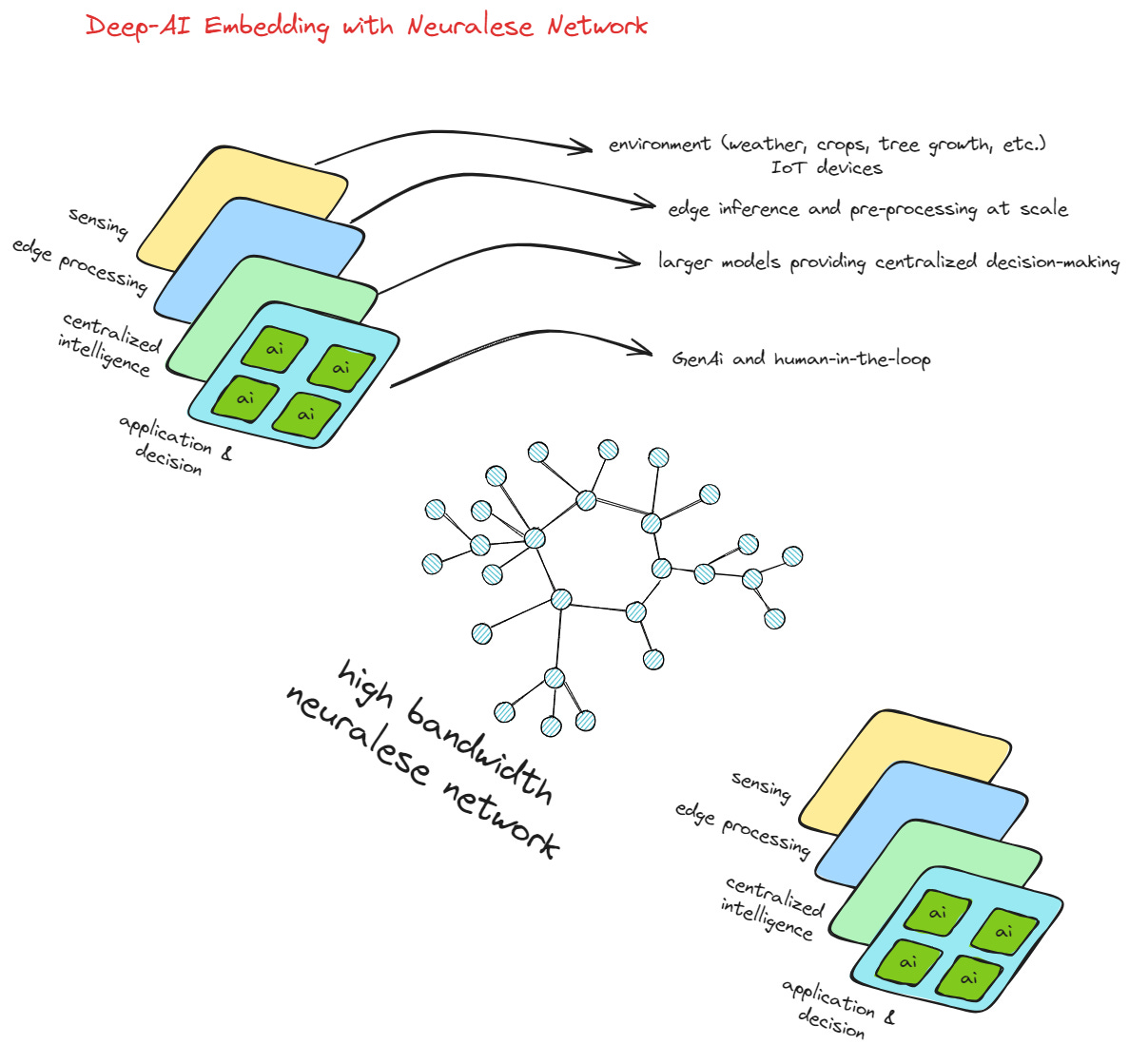
The key problem that drives local maximum issues is the absence of a well-structured and high-bandwidth intercommunication protocol that can integrate the outputs and behaviors of these individual models. I am not referring to MCP server API-style tooling. I'm talking about neuralese, but applied to the exchange of information between totally different AI models at a TCP layer level. Full neuralese intercommunication from models embedded in different layers of the physical and digital world.
The Frame Problem
Originating in the early days of AI research focused on logic-based reasoning, the frame problem in AI refers to a fundamental challenge around how an intelligent system can reason about the effects of its actions without having to explicitly consider all the things that don't change. It was first articulated by John McCarthy and Patrick J. Hayes in their 1969 paper "Some Philosophical Problems from the Standpoint of Artificial Intelligence".
When an agent performs an action, only some aspects of the world change. A significant challenge for the AI is to determine which facts remain true (the "frame") and which are altered by the action.
However, this original formulation (the frame as that which does not change) was then generalized from its narrow sense into the broader problem of relevance. In any given real-world situation, an agent (be that a human or a machine) faces combinatorialy infinite possibilities from its environment. How does an agent identify, from an effectively infinite sea of information, precisely those facts and potential consequences pertinent to a given situation or action, while ignoring the vast remainder?
This is the core of the Frame problem, that which neuroscientist John Verbaeke calls relevance realization, i.e. the process by which the human brain determines relevance in any given situation.
Verbaeke argues that there is a combinatorial explosion of possibilities when one considers a real-world dynamic situation from the point of view of the information the environment radiates. He puts forward the controlled example of a Chess game when considering ∼30 legal operations and an average of 60 turns in a game:
... the number of pathways you would have to search would be 30^60 which is a very large number. This number of paths is far too large for any conceivable computer to search exhaustively (consider for comparison that the number of electrons in the entire universe is estimated at ∼10^79) (Relevance Realization and the Emerging Framework in Cognitive Science)
This problem of relevance is intimately tied to common-sense reasoning, the seemingly effortless human capacity to understand and navigate the everyday world, make plausible predictions, grasp context, and handle ambiguity.
Another significant cognitive gap between human analysts and current AI lies in the ability to fluidly traverse different levels of analysis, dynamically shifting between scrutinizing specific, granular details (a context-dependent form of "overfitting" to the unique situation) and applying broad, generalized principles or pattern recognition.
Humans excel at this dynamic multi-level reasoning. We can zoom in on a single anomalous event treating its unique characteristics as paramount, and then instantly zoom out to consider how it fits within larger patterns or seemingly unrelated pieces of information.
This cognitive flexibility allows analysts to determine relevance dynamically, activating different mental models or reasoning pathways based on inserting some sort of JMP instructions into their thought processes based on subtle contextual cues. AI, conversely, often operates at a more fixed level of abstraction determined by its training and architecture, struggling to make these intuitive, context-driven leaps between highly specific instance analysis and broad generalization within the same investigative process.
But why is it that this fluent and dynamic traversal of different gradients of broad generalization and domain-specific problem-solving remains an obstacle for AI (ang AGI at large)? --> Because generalization is expensive.
Until Quantum Computing is generally available and a commodity, high-speed automatic self-retraining of ML models will remain prohibitive.
In Machine Learning, the primary goal is generalization. We want a model trained on a specific dataset (the training data) to perform well on new, unseen data drawn from the same underlying distribution. It can't easily extrapolate and perform well on unseen data from an entirely different data distribution. That is, not without re-training for that new distribution.
Overfitting and Underfitting
The effectiveness of AI computing artefacts depends on their ability to both solve extremely granular and specific problems on the one hand, whilst capable of solving general problems on the other. On one end of the spectrum you would have unique problems that are not extensible or transposable at all. On the other end you would have universal routines or algorithms that are used over and over to solve multiple instances of the same problem.
When pursuing Machine Learning generalization, you want to avoid two opposite pitfalls: overfitting and underfitting.
Overfitting happens when a model learns the training data too well, including its noise and specific idiosyncrasies. It essentially creates a "different solution" tailored perfectly to the training instances. When presented with new instances (unseen data), it fails because those specific idiosyncrasies aren't present. This is a failure to generalize. A computing artefact that cannot scale because its too deterministic.
Underfitting occurs when a model is too simple to capture the underlying patterns even in the training data. It fails to learn the relationships effectively. This is like a computing artefact that is too general or simplistic. It cannot even solve the specific instances it was shown (the training data) effectively, let alone generalize. It lacks the necessary complexity or "granularity" to model the problem. It fails on both seen and unseen instances.
To avoid any of these extremes and achieve stable generalization, there are three things you normally need:
Vast Amounts of Representative Data: You need enough high-quality data that accurately reflects the variety and characteristics of the real-world scenarios the model will encounter. More data often helps models generalize better and makes it harder for them to simply memorize noise (combats overfitting).
Appropriate Model Complexity (and/or Regularization): The model needs to be complex enough to capture the underlying patterns in the data (avoiding underfitting) but not so complex that it learns the noise and specific details of only the training set (avoiding overfitting).
A Robust Validation Strategy: You need a reliable way to estimate how the model will perform on unseen data during the development and tuning process. This typically involves splitting the available data into separate training, validation, and test sets.
The persistent challenges of local maxima and the frame problem reveal a critical insight: the limitations aren't just about insufficient data or algorithms. They point to a more fundamental misunderstanding of what AI needs to thrive. To break free from these constraints, we must redefine and expand our concept of an AI's Cognitive Potential.
This is the topic of our next installment, Part 3 of the Unfolding the AI Narrative series.
Until then, stay tuned, stay fresh, stay antimemetic.